前几天生产上出现一个问题,使用 spring 集成 quartz 定时器无故停住了,重启又好了。导致一些功能受到限制,查询和沟通了一段时间才解决。
描述:表象,订单状态全部卡在了一个状态下,不再改变;日志,定时器执行一段时间后不再执行,而且是所有的定时器都不执行了。
开始思考
定时器卡住了的原因可能是:
- jvm 内存爆了,导致应用停止了(第一反应是这个~因为定时器都没有设置 concurrent = false)
- 线程阻塞了,或者在等待,死锁了
spring 集成 quartz
生产上使用的 spring 版本为 3.0.5
在 spring 3.2.18 文档 看了半天才明白 spring 的定时器有两类,一类完全是 spring 代码里面编写的,一类是是集成了 Quartz。。。
常见配置
1 | <!-- 定时器注册工厂 --> |
类图
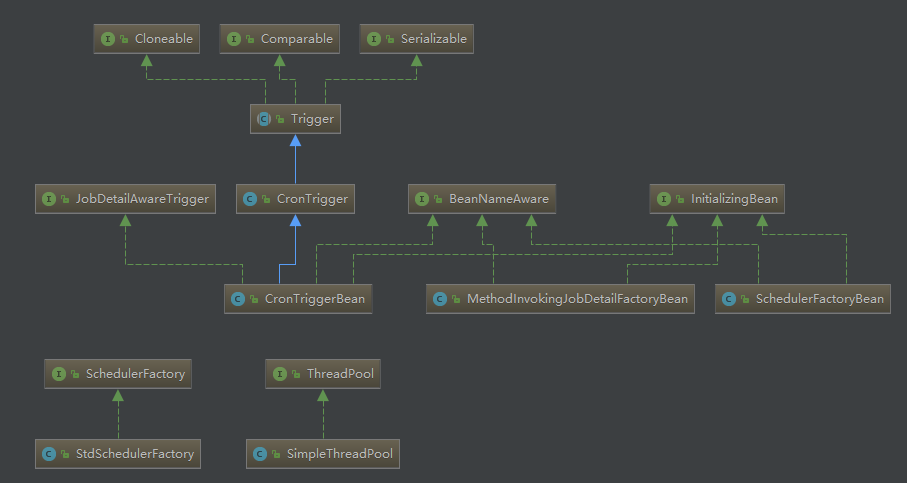
看一些代码
1 | public class SchedulerFactoryBean extends SchedulerAccessor implements FactoryBean<Scheduler>, BeanNameAware, ApplicationContextAware, InitializingBean, DisposableBean, SmartLifecycle { |
默认使用的是 org.quartz.impl.StdSchedulerFactory。StdSchedulerFactory 代码就不贴了,从中可以看出,StdSchedulerFactory 从 quartz.properties 获取相关配置。
1 | org.quartz.scheduler.instanceName = DefaultQuartzScheduler |
再进一步看 StdSchedulerFactory 代码(这里就不贴了,太长了~),可以知道使用的线程池为 org.quartz.simpl.SimpleThreadPool,默认为 10 个线程,并且配置在同一个 SchedulerFactoryBean 下的定时器使用的是同一个线程池。
开始寻找
内存
在生产上看了机器物理内存占用,发现没有什么问题(现在想想,真的是搞笑~其实查看 jvm 内存使用用情况可以使用 jmap 查看)。日志上也没有找到 OufOfMemory。
其实一般情况下,代码没有递归,没有大数量的循环,是不会产生内存溢出的,除非 jvm 参数设置得特别小。
线程
jstack pid 发现线程池中,所有线程都在干同一件事情1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41"SpringJobSchedulerFactoryBean_Worker-9" prio=10 tid=0x00007f63cc35b000 nid=0x13fa runnable [0x00007f6444aec000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:129)
at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:264)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:306)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:158)
- locked <0x0000000715c70950> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(InputStreamReader.java:167)
at java.io.BufferedReader.fill(BufferedReader.java:136)
at java.io.BufferedReader.readLine(BufferedReader.java:299)
- locked <0x0000000715c70950> (a java.io.InputStreamReader)
at java.io.BufferedReader.readLine(BufferedReader.java:362)
at org.apache.commons.net.ftp.FTPFileEntryParserImpl.readNextEntry(FTPFileEntryParserImpl.java:53)
at org.apache.commons.net.ftp.FTPListParseEngine.readStream(FTPListParseEngine.java:128)
at org.apache.commons.net.ftp.FTPListParseEngine.readServerList(FTPListParseEngine.java:104)
at org.apache.commons.net.ftp.FTPClient.initiateListParsing(FTPClient.java:3302)
at org.apache.commons.net.ftp.FTPClient.initiateListParsing(FTPClient.java:3271)
at org.apache.commons.net.ftp.FTPClient.listFiles(FTPClient.java:2930)
...
"SpringJobSchedulerFactoryBean_Worker-8" prio=10 tid=0x00007f64050ac800 nid=0x13f9 runnable [0x00007f6444b2d000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:129)
at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:264)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:306)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:158)
- locked <0x0000000716242610> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(InputStreamReader.java:167)
at java.io.BufferedReader.fill(BufferedReader.java:136)
at java.io.BufferedReader.readLine(BufferedReader.java:299)
- locked <0x0000000716242610> (a java.io.InputStreamReader)
at java.io.BufferedReader.readLine(BufferedReader.java:362)
at org.apache.commons.net.ftp.FTPFileEntryParserImpl.readNextEntry(FTPFileEntryParserImpl.java:53)
at org.apache.commons.net.ftp.FTPListParseEngine.readStream(FTPListParseEngine.java:128)
at org.apache.commons.net.ftp.FTPListParseEngine.readServerList(FTPListParseEngine.java:104)
at org.apache.commons.net.ftp.FTPClient.initiateListParsing(FTPClient.java:3302)
at org.apache.commons.net.ftp.FTPClient.initiateListParsing(FTPClient.java:3271)
at org.apache.commons.net.ftp.FTPClient.listFiles(FTPClient.java:2930)
...
都在 listFiles。然后从代码中查看到,有个 ftp 出现了卡住现象,所谓的假死。
查到这里就很容易得出结论了,由于线程池资源全部被占用,导致定时器卡死,而导致线程卡住的原因是,一个路径下的文件数量太多了。
最后处理
清理了路径下的文件,然后再进行代码上的优化。
- 把容易卡住的定时器分配到另外一个线程池中(添加一个多一个
SchedulerFactoryBean),并扩大线程池的线程数 - 缓存 listFiles 出来的文件名称,去除大量的无效操作(这是在查询问题过程中发现的)
- 如果后面观察到文件数量仍然过多,则需要提高每个线程消耗消耗文件的能力
1 | <bean id="SpringJobSchedulerFactoryBean" |
然后在 quartz.properites 中配置。
写在最后,分析类似的问题,还是多使用分析工具~因为发现当初我的猜测跟实践有很大的差别[捂脸]