概要
时间过的很快,今天我们来聊一下 redis 中的高可用和集群,如果我们是自己搭建服务,不局限于 redis,很多时候都要考虑服务的高可用,当服务出现性能问题,很多时候我们都要考虑做集群。那么怎么做可以实现 redis 的高可用呢,今天我们来聊一下以下几点:
- redis 持久化
- redis 主从复制
- redis 哨兵模式
- redis cluster
redis 持久化
我们先来聊一下 redis 的持久化,因为 redis 是基于内存的,如果没有持久化,那么重启 redis,所有数据都会丢失,并且 redis 主从复制也跟持久化有关系。那么持久化是什么,持久化就是将内存中的数据同步到磁盘来避免数据丢失
持久化方式
redis 持久化方式有两种,一种是 rdb 持久化,也叫快照,另外一种是 aof 持久化。rdb 持久化是全量复制,aof 持久化是增量复制
1 | sealde-MS-7B23# tree |
rdb 持久化方式
rdb 持久化把数据生成 .rdb 文件,比如 /var/lib/redis/dump.rdb。rdb 持久化有手动触发和自动触发,自动触发我们就不聊了,来看一下手动触发,手动触发有 save 和 bgsave 两个命令
- save 命令,会阻塞 redis,直到 rdb 持久化过程完成,可能会造成查时间的阻塞,线上不建议使用
- bgsave 命令,进程执行 fork 操作创建子线程,由子线程完成持久化,阻塞时间很短
1 | 127.0.0.1:6379> save |
因为 rdb 持久化是压缩后的二进制文件,而且是全量的,所以适用于备份、灾难恢复等。那么我们怎么备份和恢复呢,其实只要 bgsave 持久化到 dump.rdb,恢复的时候放到 redis.conf 中 dir 配置的路径下,然后重启,另外 config set dir /xxx/xxx 可以设置 rdb 文件保存的路径。这里需要注意的是如果同时开启 rdb 和 aof 持久化,恢复的时候需要特别注意,接下来会聊到这个
aof 持久化方式
rdb 持久化不是实时的,而且是全量的,每次操作都会创建新线程,频繁操作成本较高。redis 提供的 aof 持久化来解决这个问题,开启持久化可以执行命令 config set appendonly yes 或者修改配置文件 /etc/redis/redis.conf,设置 appendonly yes。aof 持久化默认是不开启的
aof 持久化流程
- 所有写入命令会 append 追加到 aof_buf 缓冲区中
- aof_buf 缓冲区向硬盘做 sync 同步
- 随着AOF文件越来越大,需定期对 aof 文件 rewrite 重写,达到压缩
- 当 redis 服务重启,可 load 加载 aof 文件进行恢复
aof 持久化相关配置
- appendonly yes 开启持久化
- appendfsync always/everysec/no 推荐使用 everysec,即每秒持久化一次
- no-appendfsync-on-rewrite no 正在 rdb 持久化,要不要停止 aof 持久化。考虑到是否 rdb 和 aof 同时进行会对磁盘有大量的 I/O 操作,aof 的 fsync 可能会阻塞很长时间,所以默认是 no 的,但有需要可以改成 yes
- auto-aof-rewrite-percentage 100 // aof 文件增长率为 100% 时,rewrite
- auto-aof-rewrite-min-size 64mb // aof 文件至少超过 64mb 时才开始 rewrite
- aof-load-truncated yes 会不会加载可能被截断的 aof 文件,yes 表示会,比如 aof 正在持久化,因为一些问题,导致没有有些字节没有写到磁盘,yes 的时候会丢弃有问题的命令然后加载成功,no 会直接报错
rdb & aof
由于 rdb 和 aof 的特性不一样,各有优势,所以一般是一起使用,但 redis 加载数据机制有个坑的地方,就是如果开启了 aof 或者同时开启了 rdb 和 aof,redis 都会加载 aof 文件,如果没有 aof 文件则会创建一个空的 aof 文件。如果刚开始使用的是 rdb方式,然后修改配置文件 appendonly yes,接着直接重启,这样 redis 会创建一个空的 aof 文件,会直接让你的数据丢失,所以千万不能这么干!!!
我们可以通过动态配置来规避这个问题,即执行命令 config set appendonly yes,然后修改配置文件,接下来就可以随便重启了,因为动态配置之后,redis 会将 rdb 数据加载到 aof 文件中。所以我们做灾备恢复的思路同样如此,先在配置文件 appendonly no,然后拷贝 dump.rdb,接下来启动,动态配置 config set appendonly yes,再接下修改配置文件 appendonly yes,这样就完成了
redis 主从复制
redis 配置主从的方式有两种
- 通过修改配置(这里包括修改配置文件和动态配置),在配置中添加
slaveof xxxx.xxx.xx.xxx 6379,xxxx.xxx.xx.xxx 为 ip 地址 - 启动的时候添加参数
redis-server --slaveof xxxx.xxx.xx.xxx 6379
动态建立主从和断开主从,执行命令 6381:> slaveof 192.169.0.1 6380 和 6381:> slaveof no one。这里有一个redis主从测试的例子
1 | ├── docker-compose.yml |
redis6380 和 redis6381 配置几乎一样,只是 redis6381.conf 加了 slaveof 192.169.0.1 6380,作为 6380 的从节点,当 6380 数据改变时,会同步到 6381 从节点
1 | 6380 设置值 name |
另外,还有一个还有一个参数 repl-disable-tcp-delay yes,默认是 no,当为 no 时 master 数据更新会立即同步到 slave 中;当为 yes 时 40 ms 才会发送一次。所以跨机房或者网络环境较差的情况下,建议为 yes
最后我们再来聊聊同步的过程,当 slave 节点启动时
- 保存 master 节点信息
- 主从建立 socket 连接
- 发送 ping 命令
- 权限验证
- 同步数据
- 持续同步数据
redis 哨兵模式
哨兵模式是 redis 迈向高可用的重要一步,高可用即当一个服务挂了,可以自动切换到另一个服务,提供不间断的服务。我们上面聊的主从复制,其实有一个很大的问题,就是如果 master 节点挂了,需要手工进行恢复,这样即麻烦又有服务较长时间的间断,哨兵模式就是为了解决这个问题
哨兵模式机制
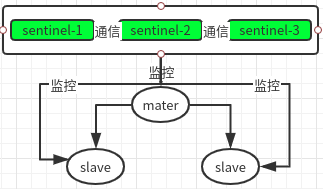
redis sentinel 官方文档 哨兵模式的机制:哨兵不停地监控着 redis 实例,当一个哨兵发现 master 实例下线,会通知其他哨兵进行确认,当多个哨兵(达到 quorum即法定人数)监控到实例下线,则认为该实例下线,然后哨兵之间会投票出领导者,然后由领导者进行故障处理。如果刚好下线的实例是 master 节点,那么会让其他实例成为 master,这个过程等会再聊
那么哨兵监控的内容有哪一些:
- 每隔 10s 会对所有 redis 实例发一次 info 请求,主要是连接情况,内存 CPU 使用情况
- 每隔 5s 利用 master 的 pulish/subscrib,发布自己的信息,比如 ip、port、runid、处理故障的能力等
- 每隔 1s 对所有 redis 实例和其他哨兵发一次 ping 请求
哨兵监控实例,还有一个主观下线和客观下线的概念。这里有两个值需要注意,一个是 is-master-down-after-milliseconds 判断是否下线的时间,如果设置成30s,就算 ping 在前 28s 内没有响应,最后 1s 有响应都视为实例可以正常工作;另一个是 is-master-down-by-addr <ip> <port> 用来在哨兵直接确认 master 节点是否下线
- 主观下线即哨兵发现 redis 实例下线了,但没有达到配置的 quorum
- 客观下线是针对 master 节点的,当达到了 quorum 的哨兵监控到 master 节点下线了,会认为客观下线了。所以 slave 节点和其他哨兵没有客观下线这个概念
故障转移
哨兵模式的故障转移会有以下几个步骤
- 确认 master 客观下线
- 选举 leader(领导者) ,leader 进行故障转移。其他哨兵称为 observers(观察着)
- leader 选择一个 slave 节点成为 master 节点
- 晋升的 slave 节点执行
slaveof no one - observers 看到晋升的 slave 节点成为 master 节点,明白故障转移开始了
- 其他 slave 节点通过
slaveof <host> <port>改变他们的 master - 当其他 slave 重新配置之后,leader 终止故障转移,将监控表(table of monitored)中移除旧 master 并用新 master 替代
- observers 检测到所有 slave 重新配置后,同样从 table 中移除 old master 并用 new master 代替
leader 的选举原理跟判断 master 节点客观下线是一样的,其中不能进行故障转移的哨兵,判断为主观下线、连接不上、ping 超过一定阈值并最迟响应的哨兵不能参与选举。leader 需要 ping 响应时间 5s 以内,runid 最小,并且在 Pub/Sub 的 channel 中表示有能力处理故障转移,最后不是 DISCONNECTED 状态。更多的条件判断请看 redis sentinel 官方文档
另外 replica-priority 可以设置 slave 节点成为 master 的优先级
配置以及测试
官网 sentinel.conf,官方的配置文件可以下载下来参考一下。在这里有个 redis-sentinel 三节点配置,模型如下,即模拟三台机器,每台机器有一个 redis 实例和 redis sentinel
1 | +----+ |
目录结构,这里有三个配置文件夹,代表三台机器的配置,每台配置通过 docker-compose up -d 启动,这里只是模拟,生产环境配置参考上面的 官方 sentiel.conf 和 redis sentinel 官方文档
1 | ├── box1 |
sentinel 的配置文件如下,需要指明监控的 master 节点,如果有密码需要添加密码
1 | port 26380 |
另外 docker-compose.yml 的配置如下,这里启动了两个 docker 容器,分别启动 redis 实例和 redis-sentinel
1 | version: '3.0' |
sentinel 配置效果如下
1 | redis sentinel 启动完后,生成自己的 ID,并开始监控 |
配置的时候需要注意的是
- 当有配置密码的时候,master 节点也需要配置密码
masterauth <pwd>,因为如果故障恢复后,再启动这个旧的 master 节点需要密码 - 如果使用 docker 或者 nat 技术的话,需要配置
sentinel announce-ip "ip地址"和sentinel announce-port 端口
另外需要注意的是,高可用是会有数据丢失的,因为 master 挂了之后,需要一定的时间进行故障转移,这段时间写入到 old master 的数据将会丢弃。当然可以配置确认故障的时候,禁止写入数据到 old master,但也会有一段时间 redis 服务不可用的问题