通过使用标准化的,广泛测试过的并发构建模块,可以消除很多潜在的线程编程风险,诸如死锁、饥饿、竞争条件(race conditions)和过度的上下文切换。
看了一下 ThreadPoolExecutor 源码的实现,觉得真的是赏心悦目。写的很漂亮,至少在我眼里是很漂亮的。
ThreadPoolExecutor 是并发实用工具(utilities)中 Task scheduling framework 里面的默认的线程池实现,具有灵活性和可扩展性。并发实用工具还有 Fork/join framework、Concurrent collections、Atomic varibles、Synchronizers、Locks 和 Nanosecond-granularity timing。有时间再去翻翻其他相关的实现,啊哈哈哈。
我阅读源码的 jdk 版本为 1.8.0_131,强烈建议先读 api文档,再阅读 jdk 的代码,会让你的思路变得清晰。
类图
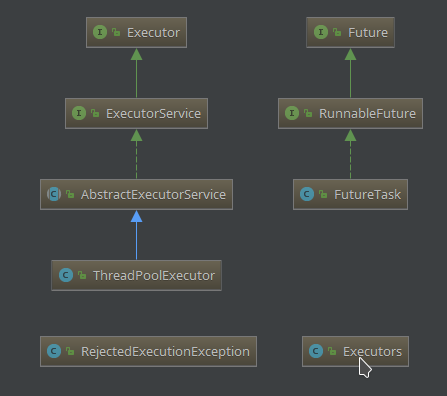
简单基本的关系图,继承关系非常清晰。其中 Future 属于任务提交后的异步结果,Executors 是创建 ExecutorService、Callable 等的工厂,RejectedExecutionException 是任务不能被接收时抛出的异常。
接下来简单看一下接口和抽象类。
Executor
1 | public interface Executor { |
Executor 接口将任务提交和线程使用的细节、调度解耦,也是该并发框架的核心,只有一个 void execute(Runnable command) 方法,通常负责创建线程。
ExecutorService
1 | public interface ExecutorService extends Executor { |
ExecutorService 更像是对 Executor 的补充,提供终止线程池、提交任务和集中处理任务。
AbstractExecutorService
1 | public abstract class AbstractExecutorService implements ExecutorService { |
AbstractExecutorService 除了实现 submit() 和 invoke() 相关的方法外,还新增了两个装饰任务的方法 newTaskFor()。这两个方法在新增任务的时候会被调用。
简单使用
官方推荐使用 Executors 创建线程池,默认创建的是 ThreadPoolExecutor,当然也可以继承 ThreadPoolExecutor, 并使用自己定义的线程池。为了简便,以下实例直接从 api 文档 中搬运过来。
1 | class NetworkService implements Runnable { |
终止线程池的方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void shutdownAndAwaitTermination(ExecutorService pool) {
pool.shutdown(); // Disable new tasks from being submitted
try {
// Wait a while for existing tasks to terminate
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
pool.shutdownNow(); // Cancel currently executing tasks
// Wait a while for tasks to respond to being cancelled
if (!pool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("Pool did not terminate");
}
} catch (InterruptedException ie) {
// (Re-)Cancel if current thread also interrupted
pool.shutdownNow();
// Preserve interrupt status
Thread.currentThread().interrupt();
}
}
使用起来很简单,只要将需要执行的任务提交给线程池即可,线程管理、调度等都会帮你搞定。但是,只有这样的功能足够优秀么?
首先有个概念,线程池“雇佣了”多名工人去执行任务。工人指的就是线程池中的线程,任务指的是原本需要创建的线程(现在交给了线程池执行)。所以节省了线程频繁创建和销毁的开销,并且可以控制线程占用资源。
ThreadPoolExecutor 还提供核心工人数的设置、预创建工人、创建新工人的 factory、工人存活时间设置、数据结构的设置、四种异常处理策略、hook、清除任务等功能。具有不错的灵活性和健壮性。
说了这么多,最想了解的还是对线程管理的那一块,很明显,就是 execute() 方法了。其余的设计放到后面再进行阅读。所以,接下来阅读的是 execute() 方法。
execute 方法
execute 方法负责创建线程和安排任务,可以说是一个调度者,考虑什么时候要加工人,安排任务需要注意什么。也是线程管理的关键。
代码
1 | public void execute(Runnable command) { |
execute() 方法做的是添加工人或将任务添加到工作队列中。其中的逻辑如下:
- 如果工人数量小于核心线程数量,则添加工人,并将任务作为初始任务给这个工人
- 否则将任务添加到工作队列中(
workQueue.offer(command)),并做二次校验(校验是否应该添加工人) - 尝试添加核心线程数以外的工人,如果仍失败,则拒绝本次任务的提交
看到这里,是不是觉得几行代码就将核心工程完成了!那么,任务交给谁去完成了呢?这就需要看一下内部类 Worker 了,所以真正干活的是工人。
工人 Worker
首先看一下工人的日常生活
此处应有动画 [捂脸],然而我的前端技术限制了我的想法。总之,工人就是不断地从任务队列中获取任务,然后不断地完成任务。
从下面过来的朋友1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
...
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
public void lock() { acquire(1); }
public void unlock() { release(1); }
...
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
由于想简单说说这个 Worker 的日常,所以只截取其中一段代码。
- 首先,worker 有两个重要的变量,
thread和firstTask。 - Worker 构造函数中,可以看出,
thread还是worker自身,firstTask是构造时候赋值的,表示第一个任务。 - 除了构造方法,还有一个方法是
run()方法,run()方法调用了runWorker()方法。 runWorker()方法,就是在 worker 线程中,不停地getTask(),然后去调用获取到的任务的task.run()方法。也就相当于不停地干着获取到的任务。
到这里,我们知道了 execute 方法会添加 task 和 worker,然后 worker 只要开始干活了,即 worker 这个线程 start() 了,worker 就会不停地完成 task。
那么 worker 又是什么时候开始工作的呢?也就是什么时候开始 start() 的呢?这就要看上面 excute 方法里面调用的 addWorker() 方法。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
addWorker 方法只干两件事情
- 在条件允许的情况下,添加工人(
compareAndIncrementWorkerCount()接着new worker() 然后workers.add(w)) - 让工人开始干活(
t.start())
好了,到这里,主要的流程都明白了。当然,还有异常处理等流程还没有看,接下来也许会看。那么有几个问题,如果当多个线程同时去获取一个任务的时候怎么处理?怎么保证线程池中的工人数量跟预期的是一样的?(比如,你认为有 10 个工人,实际可能有1000个工人)当任务失败了,是怎么处理工人的呢?…
防止争抢任务
当多个线程同时获取一个任务的时候,这里线程池是通过阻塞队列这一数据结构,实现在多线程情况下数据的安全性。先来看看 getTask() 方法,getTask() 方法有以下一句。1
2
3Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();timed 是 boolean 类型,条件是设置了核心线程超时或者当前工人数大于核心线程数为 true。不论是 true 还是 false,都是从 workQueue 获取任务。1
private final BlockingQueue<Runnable> workQueue;
workQueue 是阻塞队列。BlockingQueue 有多个实现,我们可以挑其中一个常见的来看看,比如 LinkedBlockingQueue。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
...
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
...
}
明显地,每次获取任务的时候,通过 takeLock 和 putLock 保证只有一个线程在 获取/放入 任务,从而防止多个线程获取到同一个任务的尴尬。poll() 方法的实现跟 take() 方法实现类似,这里不再贴上代码。
当然,这里也可以学习到如何运用 ReentrantLock 和 Condition 进行阻塞和解掉阻塞的操作。详细的使用,会再开一篇文章进行讨论,以及测试。
线程池状态和工人数
为什么会把线程池状态和工人数一起说呢?因为在线程池中,线程状态和工人数共同打包成一个整数,然后以掩码的形式对这个整数进行解包获取。掩码是什么呢?简单理解就是与或非运算。
打包成一个整数
表示状态的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
再来看看下面这个表格,你就会理解,哪些是打包的,哪些是解包的,以及这个思路是怎么样的。
| 变量 | 二进制 | 十进制 |
|---|---|---|
| COUNT_BITS | 29 | |
| CAPACITY | 00011111111111111111111111111111 | |
| ~CAPACITY | 11100000000000000000000000000000 | |
| RUNNING | 11100000000000000000000000000000 | -536870912 |
| SHUTDOWN | 00000000000000000000000000000000 | 0 |
| STOP | 00100000000000000000000000000000 | 536870912 |
| TIDYING | 01000000000000000000000000000000 | 1073741824 |
| TERMINATED | 01100000000000000000000000000000 | 1610612736 |
看到这里,你就会发现整数一共 32 位,前 3 位表示状态位,后 29 位表示工人数,也就是最多可以有 CAPACITY = (2^29) - 1 个工人数。
使用移位以及掩码的设计其实很常见,像雪花算法就有类似的设计~
线程池的状态
其实当你赋予一个对象状态,可以说你给了它生命,状态变化的过程,也就可以称之为生命周期。通常这些状态的变化都是有一定的规则去约束的。这里简单地说一下线程池的状态。
线程池的状态如上面表格所示,一共有 5 种。分别为:
- RUNNING: 接收新的任务并且处理队列中的任务
- SHUTDOWN: 不接收新的任务,但是处理队列中的任务
- STOP: 不接收新的任务也不处理队列中的任务,并且中断正在执行的任务
- TIDYING: 所有任务都已经终止,工人数为 0,这个状态将会执行
terminated()方法 - TERMINATED:
terminated()方法已经执行完
如果对状态的变化实现感兴趣,可以看一下 advanceRunState() 和 tryTerminate() 这两个方法。特别地,terminated() 是一个 protected 方法,目的在于子类覆盖这个方法时,会在 TIDYING -> TERMINATED 时执行。
了解线程池的生命周期,也有助于阅读源码时候的分析。在这里不详细说工人数的增减,可以查看 execute() 方法和 runWorker() 方法。
我们来聊聊设计
起初我想看 ThreadPoolExecutor 线程池的源码,是因为好奇它是怎么完成线程池概念的,以及我想学习一个框架是怎么设计的。因为最近我在项目中想重新设计某个模块的结构,尝试设计,但是失败了,所以想借鉴一下。
其实只是单纯地实现某个功能,这个模块可以不用设计,但是,只要想让这个模块好用,也就是灵活性和扩展性好,那么就需要花心思了。想要窥探一个框架的扩展性,我觉得可以从 构造方法 和 protected 方法入手。
ThreadPoolExecutor 的构造方法
直接看参数最多的构造方法1
2
3
4
5
6
7
8
9public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
这里有核心线程数和最大线程数的设置,线程存活时间的设置,有数据结构阻塞队列的设置,线程工厂的设置,拒绝异常处理的设置(任务被拒绝)。可以看得出来,一般都把常用的配置放置到构造函数中,给使用者进行选择。当然,也可以通过 set() 方法进行设置。
而像 allowCoreThreadTimeOut(),ensurePrestart()等配置,则没有体现在构造函数上。当然,像功能上的方法,则肯定不能在构造函数中了,比如 remove(Runnable task),purge()。
protected 方法
首先从 ThreadPoolExecutor 的父类 AbstractExecutorService 开始。
newTaskFor
1 | protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { |
这里提供默认包装任务的实现,并返回了包装后的结果。这里有很重要的一点,至少对我来说很重要,即包装之后返回了一个接口。
仔细想一下,为什么有这么一个返回,本身 Runnable.run() 是没有返回的;为什么返回的是接口。可能你在编程中,会遇到返回固定类型的,比如某个请求后指定的返回对象;会遇到返回某中数据类型的,其实也是接口,比如 Map、TreeMap等;会遇到返回抽象类型的,抽象类型有公共的一些变量;会遇到根据参数,通过反射获取返回类型的。
返回类型的设计五花八门,各有各的好处,当然有些坏处也特别明显(就是扩展性不好,使用起来不够顺手)。我也是最近才发现这种设计的,这种设计其实在很多源码当中经常使用。
就算返回很简单,也可以包装一下,为的就是利用面向对象的多态性质。比如 javax.xml.ws.Response 接口,其实返回的是 Map<String,Object>,但就是要来这么一手,啊哈哈哈。
beforeExecute、afterExecute 和 terminated
beforeExecute()、afterExecute() 就是所谓的 hook(不知道如何正确解释 hook =。=)。这个两个方法使用在 runworker() 中,可以在执行任务前后做点什么。
将动作延后到子类当中,这样的设计也是非常常见的。
terminated() 同样如此,详细可以查看 tryTerminate() 方法。
finalize
还有一个 finalize() 方法,但是这个是 Object 的方法,是在对象没有被引用,GC 之前会调用的方法。通常进行释放资源等操作。
如何去设计
对于面向对象,我一直在摸索(虽然也没摸索多久~),我也没有什么好的经验。只能在这里立 flag,然后去实践,然后再总结,再实践…
但是把线程池一路看下来,我决定按照以下思路去进行实践,以后有机会再回来说明效果如何。大致就是先设计 api,然后再去实现。
- 首先确定模块的核心功能,并定义为接口。比如这里的
Executor接口 - 补充必要的辅助功能,并继承核心接口
- 接口的参数和返回值可以考虑使用接口,充分发挥多态
- 围绕核心功能进行实现,实现的时候将职责分开,谁该干嘛就交给谁干
- 最后将常用的配置放到构造函数,并且必要时开放一些方法给子类去实现
- 如有必要,提供工厂,用于创建常用配置的实现。如
Executors